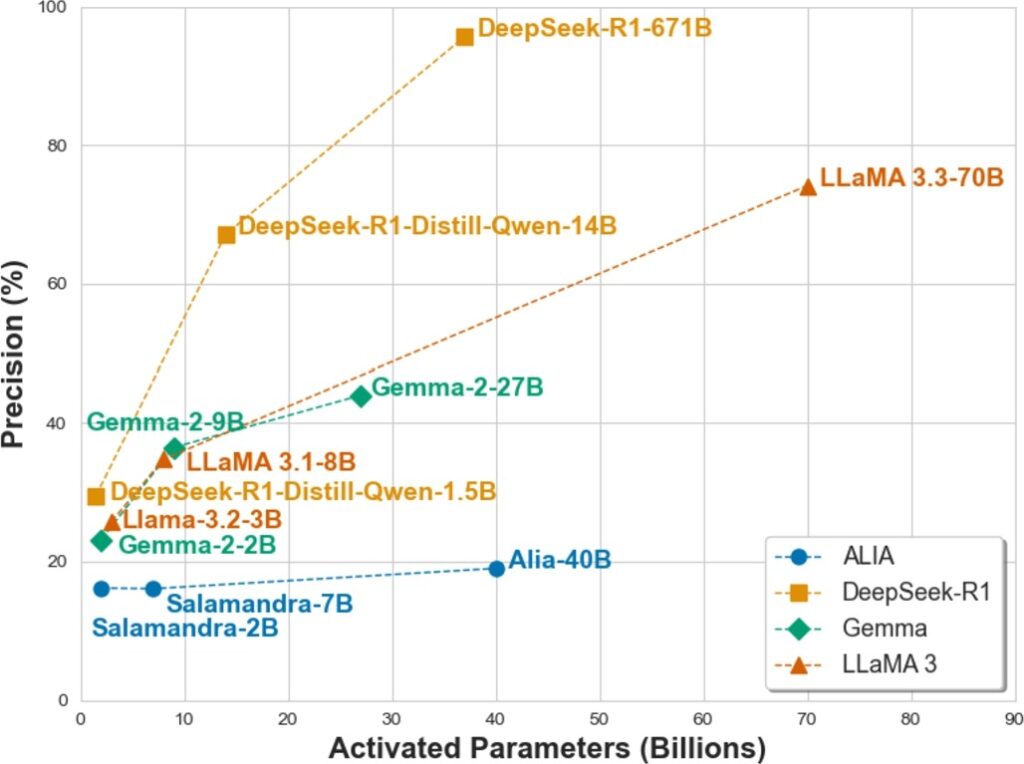
Large Language Models (LLMs) have revolutionized Artificial Intelligence (AI), with OpenAI’s reasoning models and, more recently, DeepSeek reshaping the landscape. Despite AI being a strategic priority in Europe, the region lags behind global leaders. Spain’s ALIA initiative, trained in Spanish and Catalan, seeks to bridge this gap. We assess ALIA and DeepSeek’s performance against top LLMs using a dataset of high-school-level mathematical problems in Catalan from the Kangaroo Mathematics Competition. These exams are multiple-choice, with five options. We compiled each LLM’s solution and the reasoning behind their answers. The results indicate that ALIA underperforms compared to all other evaluated LLMs, scoring worse than random guessing. Furthermore, it frequently failed to provide complete reasoning, while models like DeepSeek achieved up to 96% accuracy. Open-source LLMs are as powerful as closed ones for this task. These findings underscore challenges in European AI competitiveness and highlight the need to distill knowledge from large models into smaller, more efficient ones for specialized applications.
LLM performance on mathematical reasoning in Catalan language