{kind=link}
Our recent paper Potential limitations in COVID-19 machine learning due to data source variability: A case study in the nCov2019 dataset has been accepted for publication in J Am Med Inform Assoc. (JAMIA, IF 4.112). We study whether the lack of representative coronavirus disease 2019 (COVID-19) data is a bottleneck for reliable and generalizable machine learning. Data sharing is insufficient without data quality, in which source variability plays an important role. We showcase and discuss potential biases from data source variability for COVID-19 machine learning. Our results are based in the publicly available nCov2019 dataset, including patient-level data from several countries. We aimed to the discovery and classification of severity subgroups using symptoms and comorbidities. We show that cases from the 2 countries with the highest prevalence were divided into separate subgroups with distinct severity manifestations. This variability can reduce the representativeness of training data with respect the model target populations and increase model complexity at risk of overfitting. 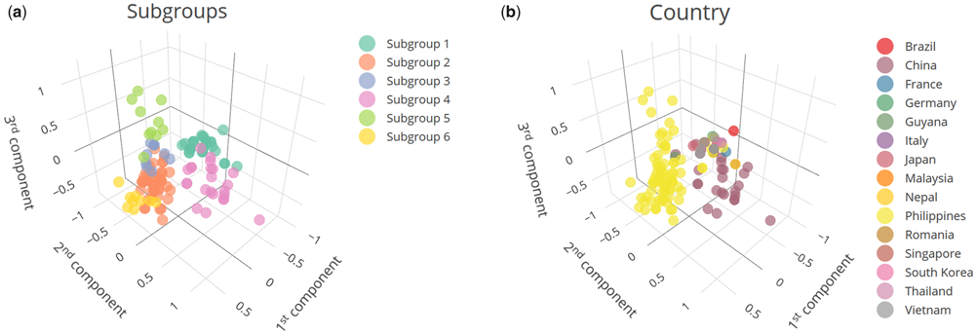
Potential limitations in COVID-19 machine learning due to data source variability
